
Have you ever felt lost in the labyrinth of git branching? We’ve been there! Over the years, we’ve navigated through a myriad of git branching strategies – some successful, while others… not so much. But, through trial and error, we’ve honed an approach that’s been a game-changer for us.
The Evolution of Our Git Strategy
We’ve tailored Git-Flow to align with our unique needs and business model. As a dynamic software development agency handling a multitude of clients and a myriad of projects – ranging from short-term tasks to multi-year endeavors – we’ve recognized the importance of a streamlined git process.
This strategy not only optimizes the utility of our git repository tools but also ensures smooth progress, enabling faster software development. This efficiency has not only been beneficial for our team but is a quality our clients deeply appreciate, resulting in lasting collaborations.
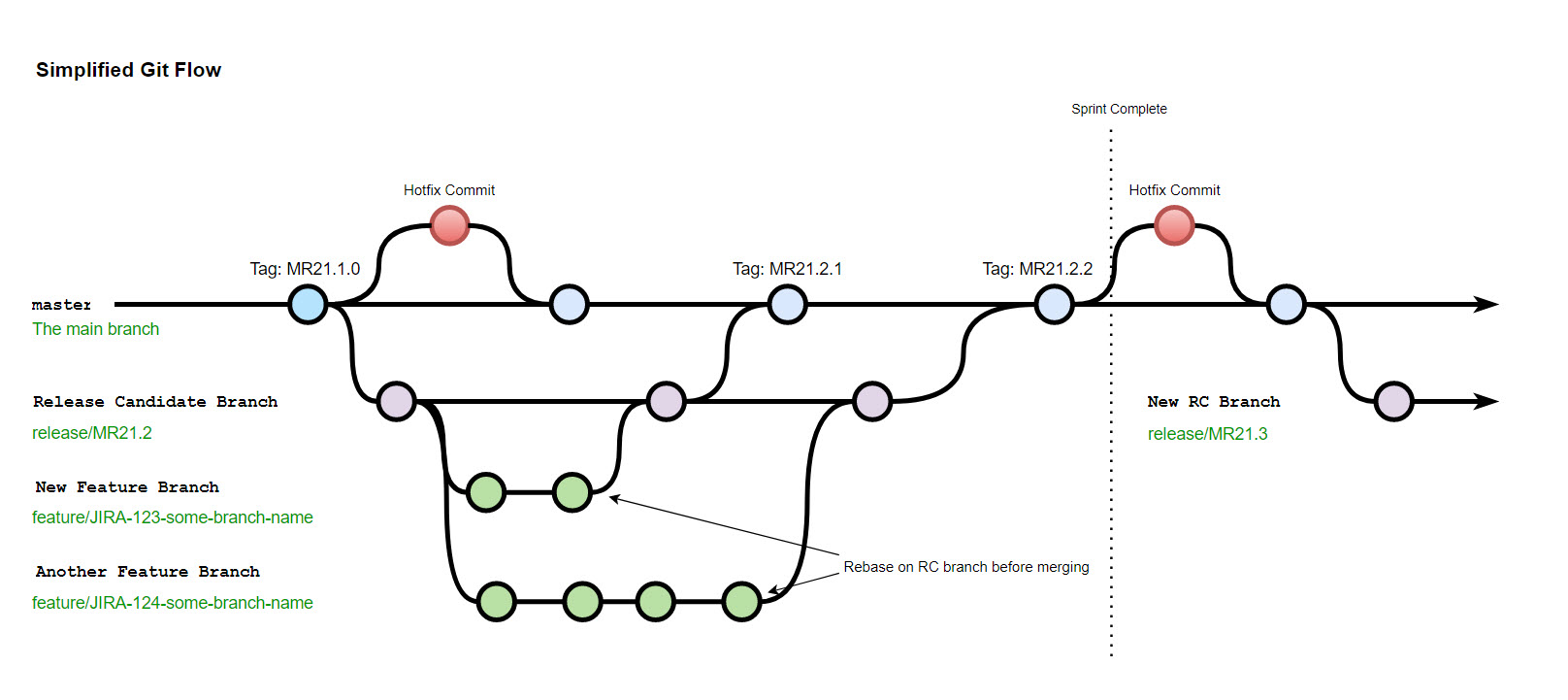
Understanding Our Modified Git Flow
Comparing our method with Vincent Driessen’s original Git Flow, the most noticeable change is the removal of the develop branch. Though this might seem like a significant deviation, the advantages we’ve experienced have outweighed the cons.
6 Essential Rules to Our Approach
- Rule 1: Always deploy from the master branch for production. This ensures that only well-refined, tested, and functional code, based on the latest completed release, makes it to production.
- Rule 2: Post deployment, initiate your release branch from the master. Once a release passes all UAT checks and has the team’s consensus, deploy it. Subsequently, tag the master with the latest version and discard all other branches. This cleanliness prevents lingering codes from creating confusion or potential errors.
- Rule 3: Avoid merging master into release or vice versa. In simpler terms, always merge upward, never downward.
- Rule 4: Integrate hotfixes to both master and release branches simultaneously. This ensures both branches maintain the highest code integrity. In case of merge conflicts, prioritize the hotfix’s code as it is the most stable for production.
- Rule 5: Keep feature branches ephemeral and rebase frequently. If a branch exists for more than a couple of days, it’s likely too extensive and should be segmented further. This minimizes risk and simplifies the integration process.
By adhering to these guidelines, not only have we streamlined our workflow, but we’ve also enhanced collaboration and reduced potential errors, ensuring the delivery of top-tier software solutions.
Conclusion
Embarking on a journey of continuous improvement is the hallmark of any successful team. We believe that our modified Git branching strategy is a testament to this ethos. We encourage you to test our approach, adapt it to your needs, and share your experiences with the wider developer community.





